Introduction
This is a sample native workflow for audio-driven video generation using Wan2.2-S2V, based on ComfyUI.
We are pleased to announce that Wan2.2-S2V, our advanced audio-driven video generation model, is now natively supported in ComfyUI! This powerful AI model transforms static image and audio input into dynamic video content, supporting a variety of creative content needs, such as dialogue, singing, and performance.
Model Highlights
- Audio-Driven Video Generation: Converts static images and audio into synchronized videos
- Cinematic Quality: Generates high-quality videos with natural expressions and movements
- Minute-Level Generation: Supports long-duration video creation
- Multi-Format Support: Applicable to both full-body and half-body characters
- Enhanced Motion Control: Generates motion and environments based on text commands
Recommended machine:Ultra-PRO
Workflow Overview
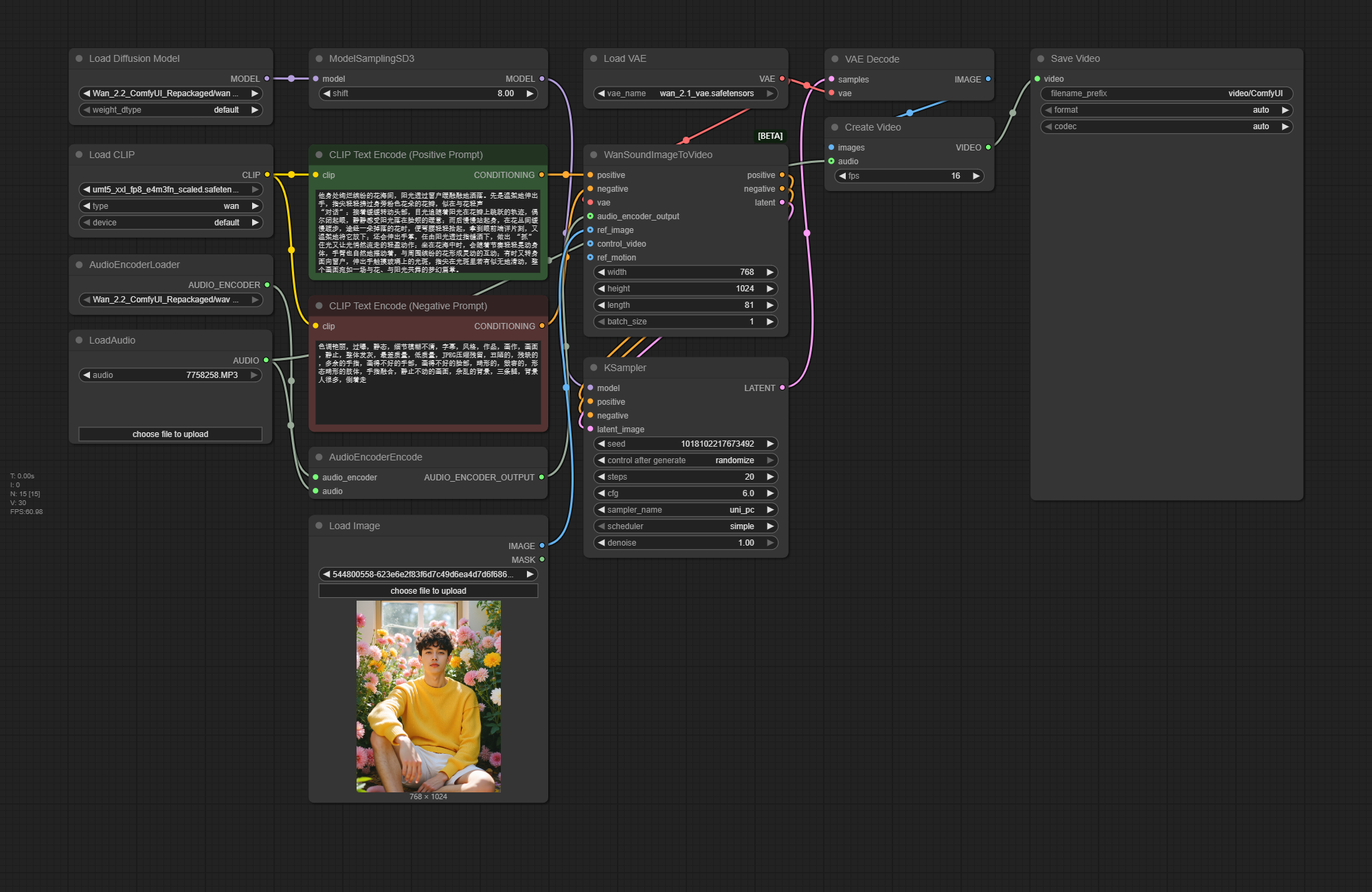
How to use this workflow
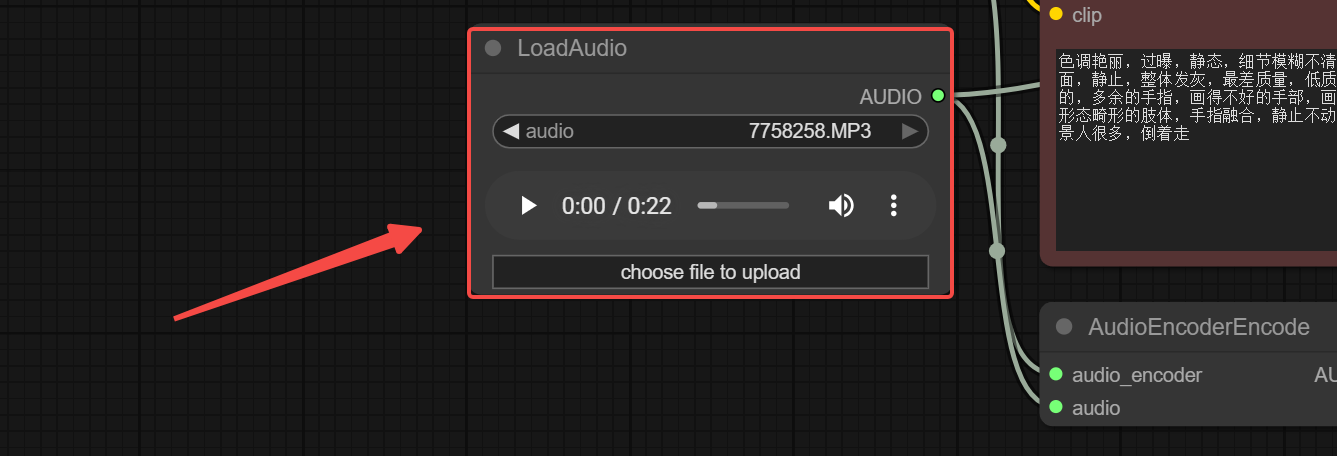
Step 1: Load Audio
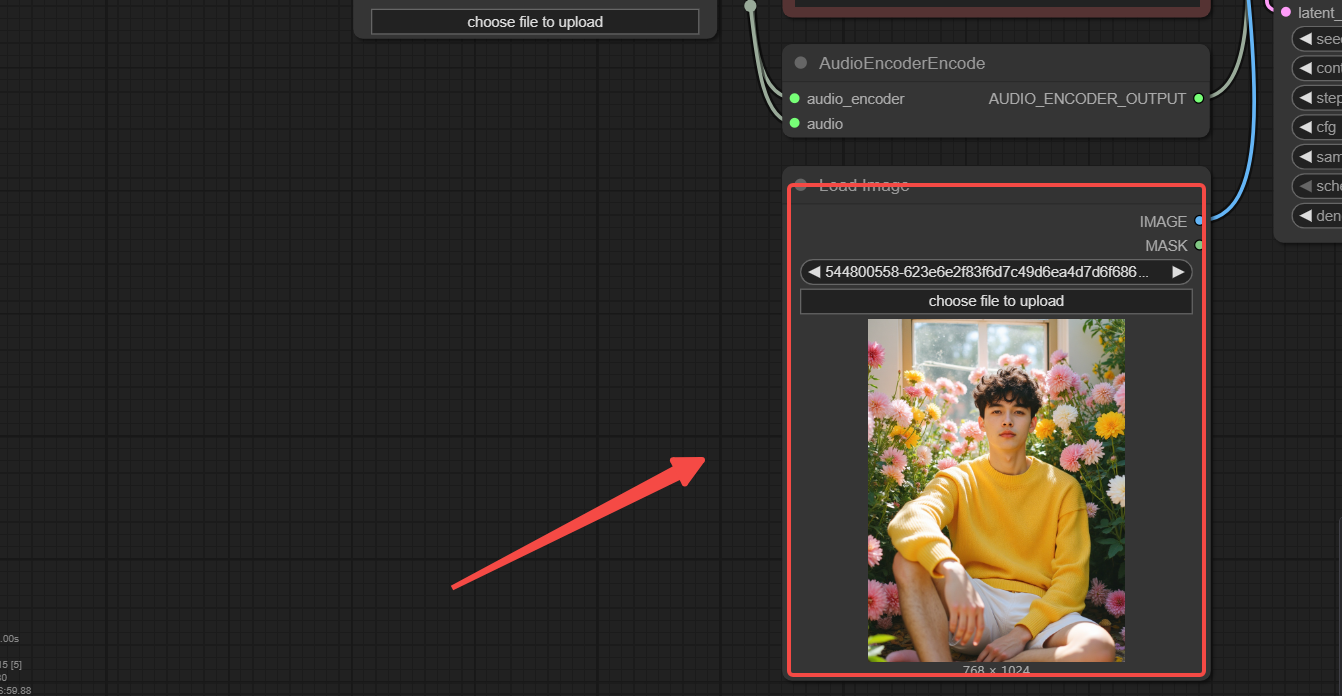
Step 2: Load Image
Step 3: Input the Prompt
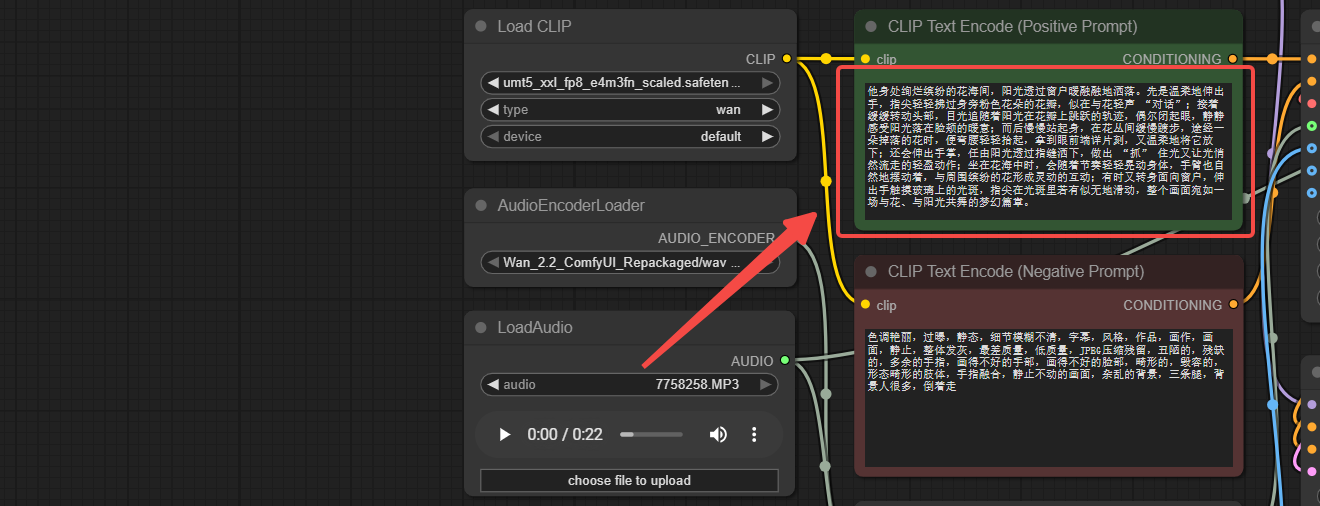
Step 4: Set FPS
Usually, the default settings are sufficient without requiring multiple modifications.
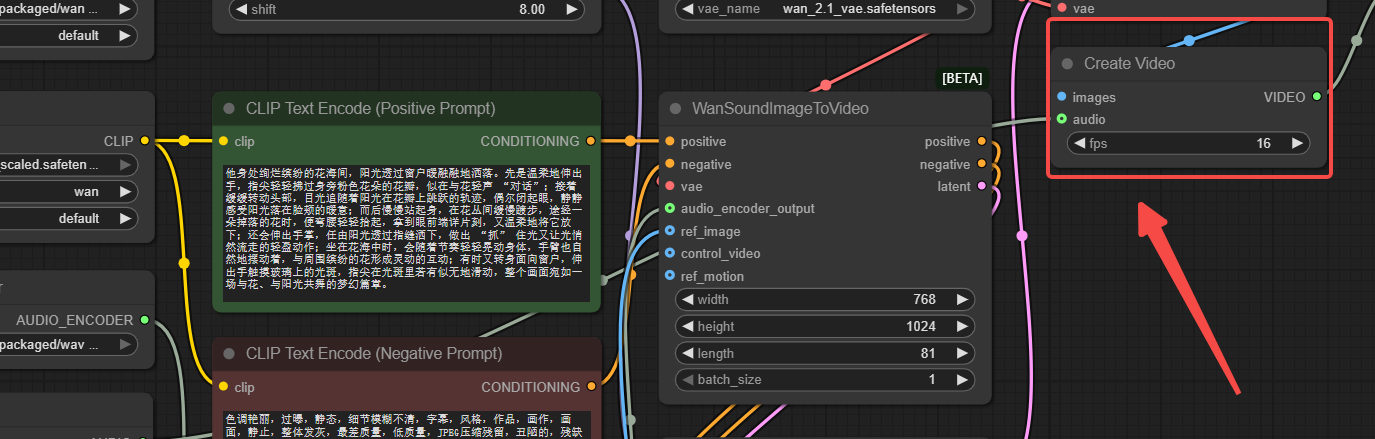
Step 5: Get Video
You can change the video length by setting frame_rate or num_frames (in WanVideo Empty Embeds). Video length = num_frames/fps