
The WAN 2.2 S2V Workflow is the latest evolution of WAN 2.2, designed to create cinematic HD-quality talking or singing videos with minimal effort. This powerful sound-to-video and video-to-video lipsync workflow for ComfyUI allows you to synchronize audio with video seamlessly, producing realistic lip movements and smooth motion in record time.
At this node (AudioCrop), you need to specify which part of the uploaded audio you want to use in your workflow. Set the start_time and end_time values so that the cropped audio matches the exact segment of speech you want.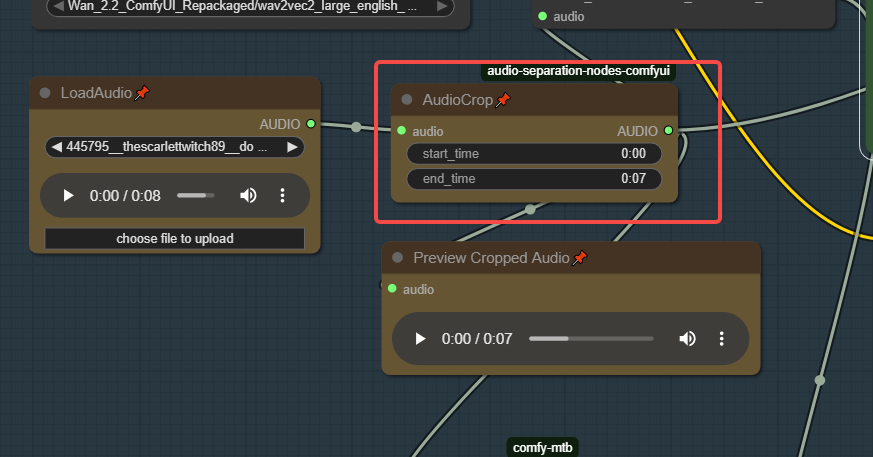 Key Features:
Key Features:
- 🎤 Audio + Video Input – Upload an audio/music file along with a video of a person or character to generate synced talking or singing outputs.
- 🎥 Automatic Frame Matching – No manual frame calculation required—the workflow intelligently adjusts frame count to match the audio duration and aligns it with the video length.
- ⚡ Fast & Reliable – Optimized for WAN 2.2 sound-to-video fast workflow execution. The first run may take longer, but subsequent runs are significantly faster.
- 🖼 Cinematic HD Quality – Produces vibrant, detailed visuals with natural lip sync precision.
- 🔧 Resolution Control – Adjust output resolution to balance render speed with visual quality.
- 📘 User-Friendly – Designed to be as simple as possible: upload, queue, and generate.
Pro Tips:
- Use ULTRA PRO GPU for best speed and quality results.
- Higher output resolutions require more generation time—choose wisely for your needs.
- Ideal for AI music videos, talking avatars, dubbing projects, character animations, and storytelling content.
With the WAN 2.2 S2V Workflow, creating high-quality lip-synced videos is easier than ever. Just upload your audio + video, write a prompt, and let the workflow handle the rest—delivering smooth, cinematic results every time.