Introduction
Wan2.2 is the industry's first video generation model to successfully implement a Mixture-of-Experts (MoE) architecture. This groundbreaking approach unlocks new levels of quality and detail by using specialized "expert" models for different parts of the video generation process, all without increasing the computational cost.
- 👍 Effective MoE Architecture: Wan2.2 introduces a Mixture-of-Experts (MoE) architecture into video diffusion models. By separating the denoising process cross timesteps with specialized powerful expert models, this enlarges the overall model capacity while maintaining the same computational cost.
- 👍 Cinematic-level Aesthetics: Wan2.2 incorporates meticulously curated aesthetic data, complete with detailed labels for lighting, composition, contrast, color tone, and more. This allows for more precise and controllable cinematic style generation, facilitating the creation of videos with customizable aesthetic preferences.
- 👍 Complex Motion Generation: Compared to Wan2.1, Wan2.2 is trained on a significantly larger data, with +65.6% more images and +83.2% more videos. This expansion notably enhances the model's generalization across multiple dimensions such as motions, semantics, and aesthetics, achieving TOP performance among all open-sourced and closed-sourced models.
- 👍 Efficient High-Definition Hybrid TI2V: Wan2.2 open-sources a 5B model built with our advanced Wan2.2-VAE that achieves a compression ratio of 16×16×4. This model supports both text-to-video and image-to-video generation at 720P resolution with 24fps and can also run on consumer-grade graphics cards like 4090. It is one of the fastest 720P@24fps models currently available, capable of serving both the industrial and academic sectors simultaneously.
https://github.com/Wan-Video/Wan2.2?tab=readme-ov-file
Recommended machine:Ultra-PRO
Workflow Overview
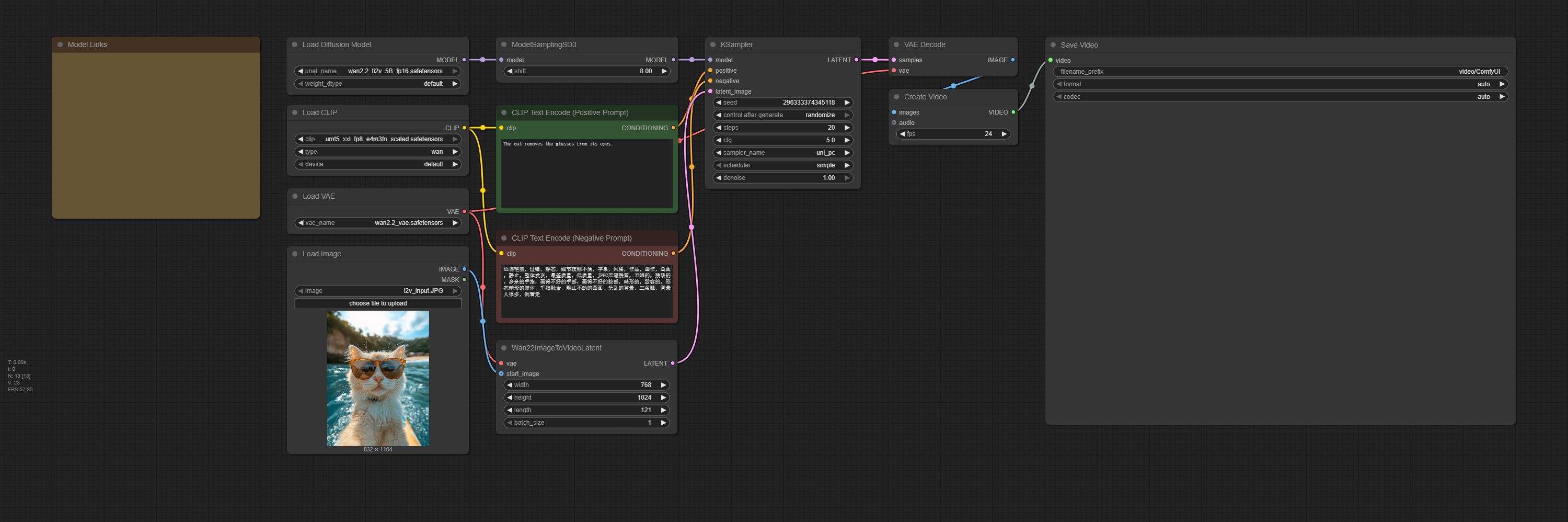
How to use this workflow
Step 1: Load Image
If you only want to pass the video, just bypass the Load Image node.
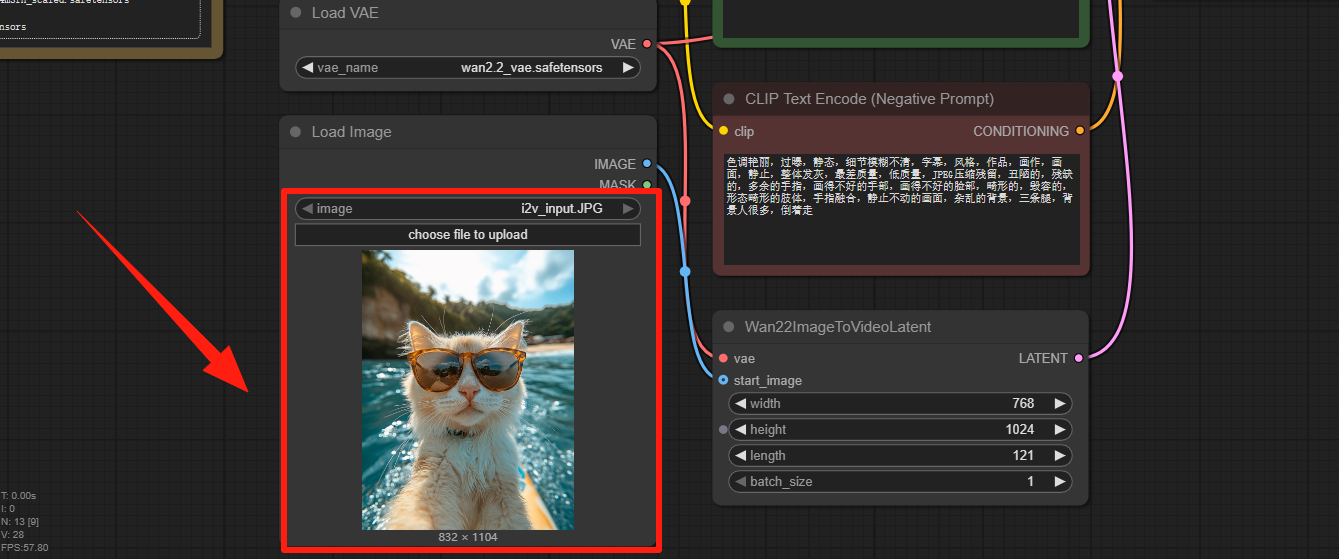
Step 2: Adjust Video parameters
Adjust the resolution, length under 81 frames doesn't seem to work
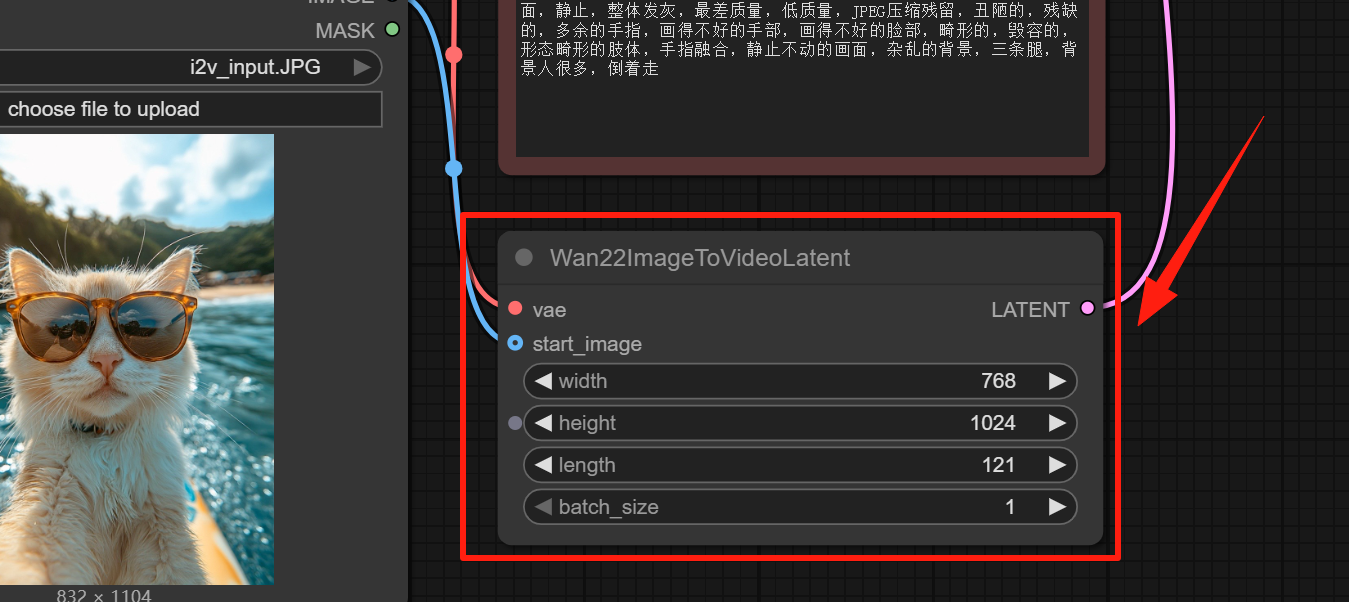
Step 3: Input the Prompt
If you are generating video from images, no need to describe the entire picture in detail, just enter key information such as lens, action, etc.
If you're generating a video from text, it's best to describe the image content in great detail. However, even the most detailed prompts are limited by the model, and the quality of the generated image will be far inferior to 14B.
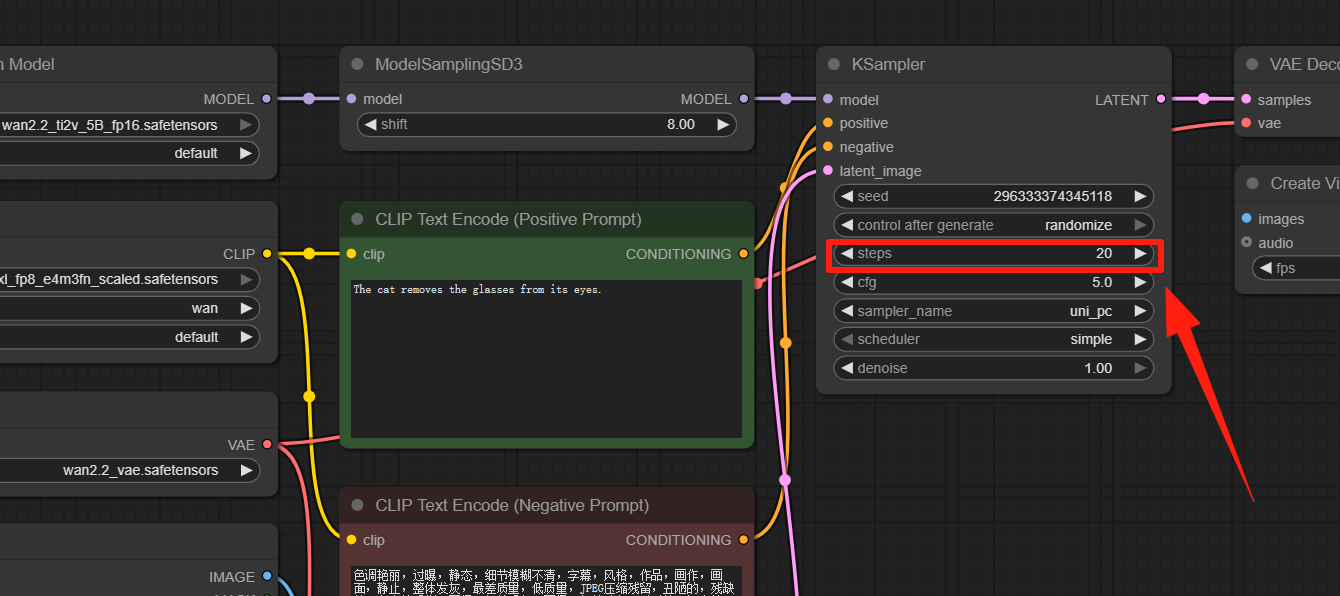
Step 4: Set the number of sampler steps
If you are generating images-based videos, a step of 20 will produce very high-quality videos.
If you are generating images-based videos, a step of 30 or higher is recommended.
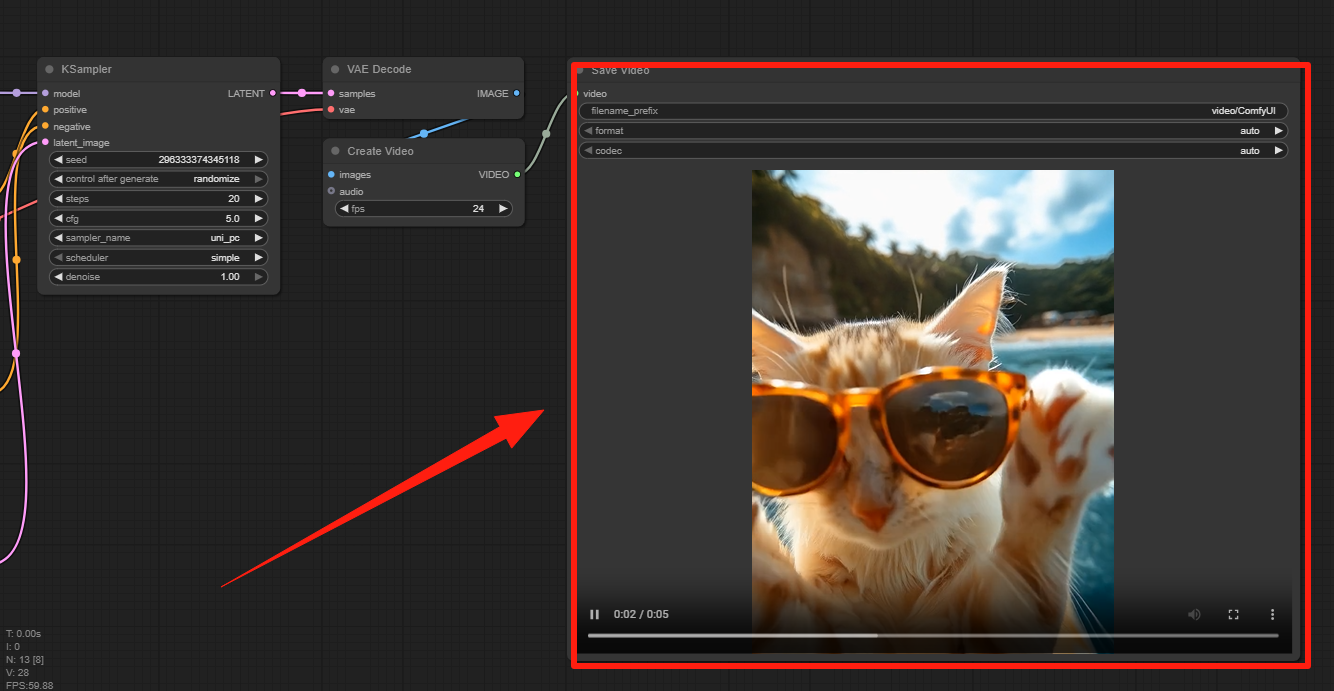
Step 5: Get Video