Introduction
A comprehensive ComfyUI integration for Microsoft's VibeVoice text-to-speech model, enabling high-quality single and multi-speaker voice synthesis directly within your ComfyUI workflows.
Core Functionality
- 🎤 Single Speaker TTS: Generate natural speech with optional voice cloning
- 👥 Multi-Speaker Conversations: Support for up to 4 distinct speakers
- 🎯 Voice Cloning: Clone voices from audio samples
- 📝 Text File Loading: Load scripts from text files
- 📚 Automatic Text Chunking: Handles long texts seamlessly with configurable chunk size
- ⏸️ Custom Pause Tags: Insert silences with
[pause]and[pause:ms]tags (wrapper feature) - 🔄 Node Chaining: Connect multiple VibeVoice nodes for complex workflows
- ⏹️ Interruption Support: Cancel operations before or between generations
https://github.com/Enemyx-net/VibeVoice-ComfyUI
Recommended machine:Large-Pro
Workflow Overview
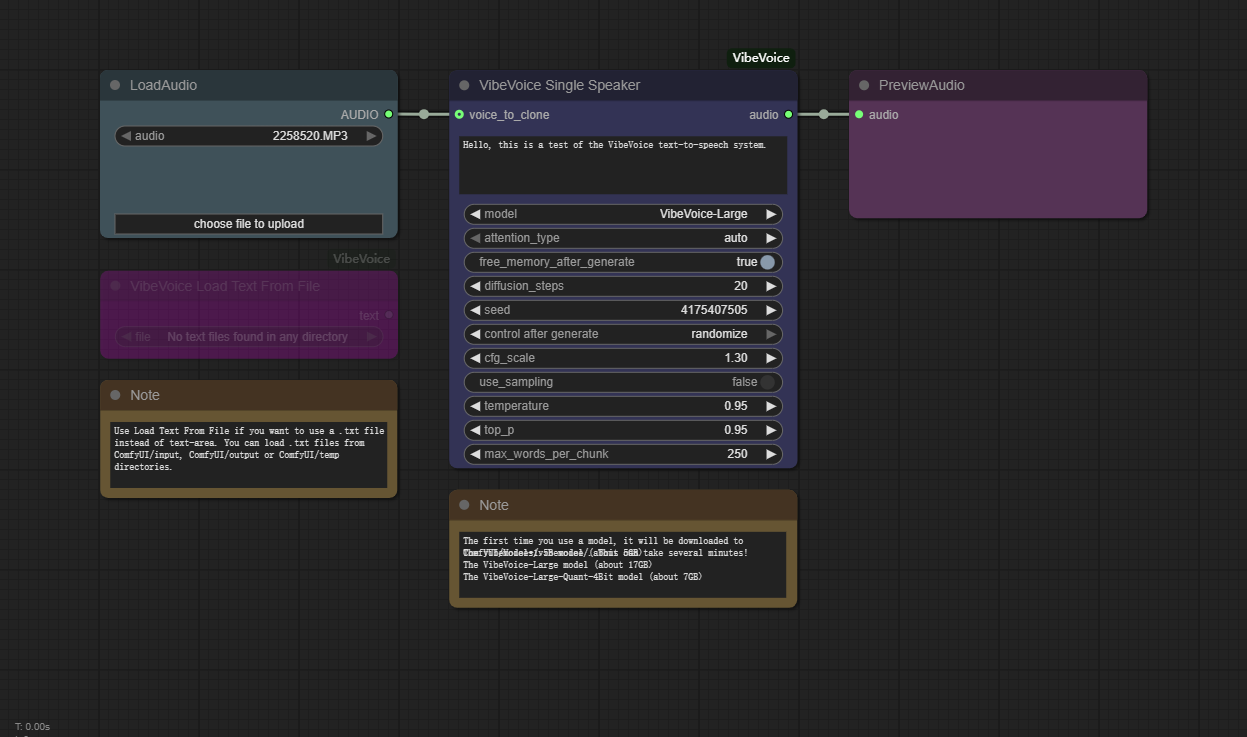
How to use this workflow
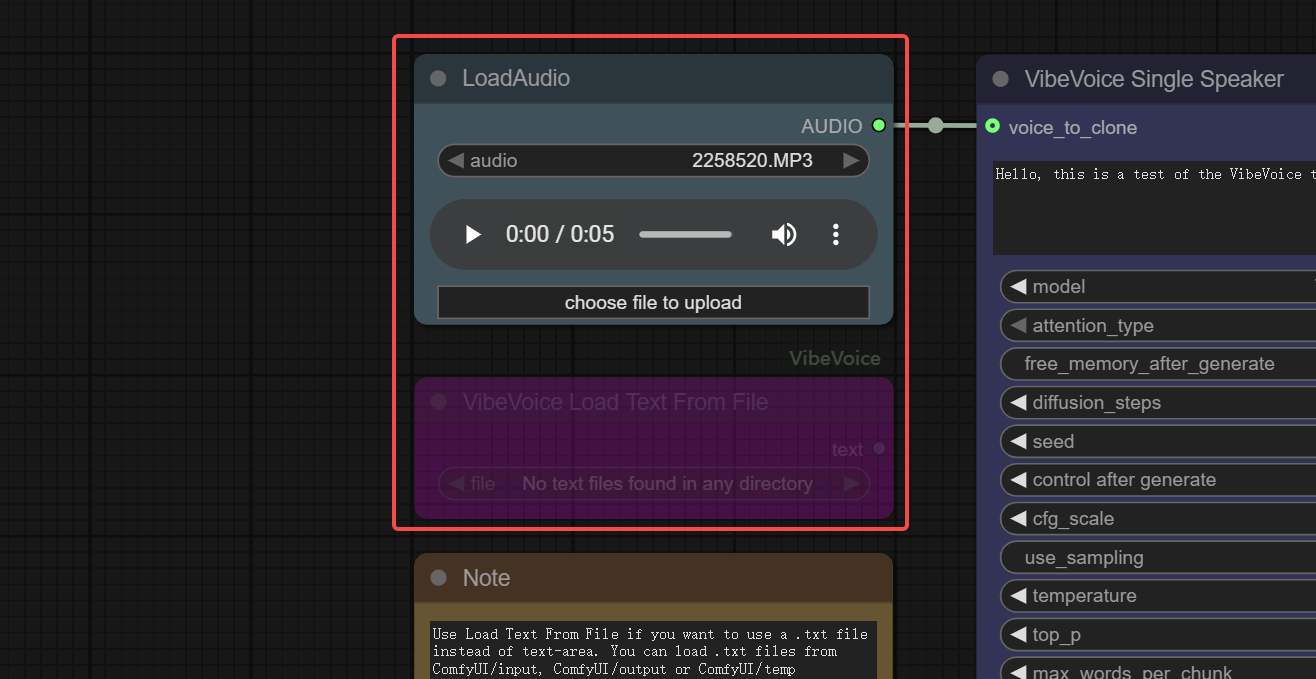
Step 1: Load Audio
Use Load Text From File if you want to use a .txt file instead of text-area. You can load .txt files from ComfyUI/input, ComfyUI/output or ComfyUI/temp directories.
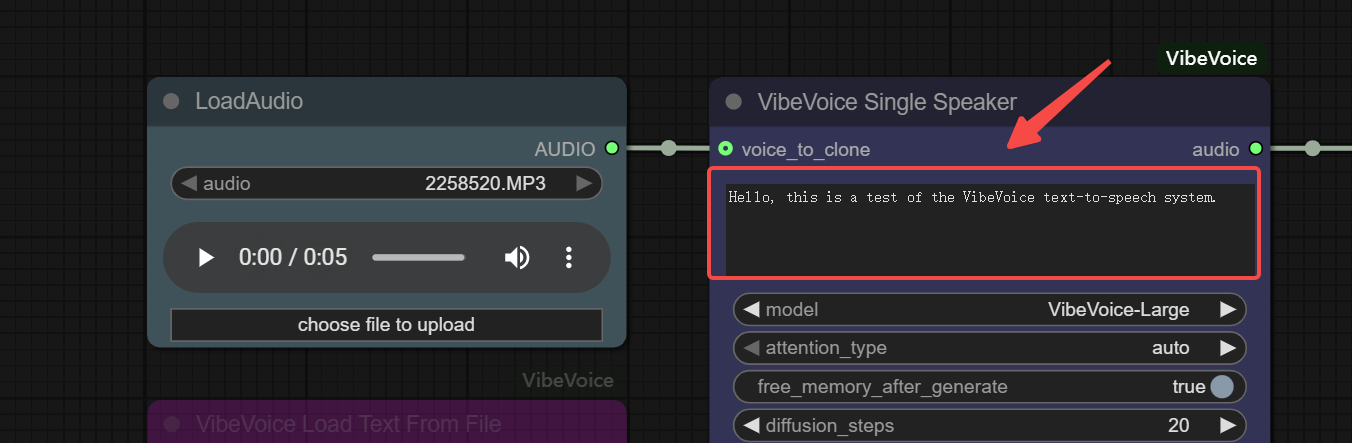
Step 2 : Input the Prompt
Step 3 : Choose Model
The first time you use a model, it will be downloaded to ComfyUI/models/vibevoice/. This can take several minutes!
The VibeVoice-1.5B model (about 5GB)
The VibeVoice-Large model (about 17GB)
The VibeVoice-Large-Quant-4Bit model (about 7GB)
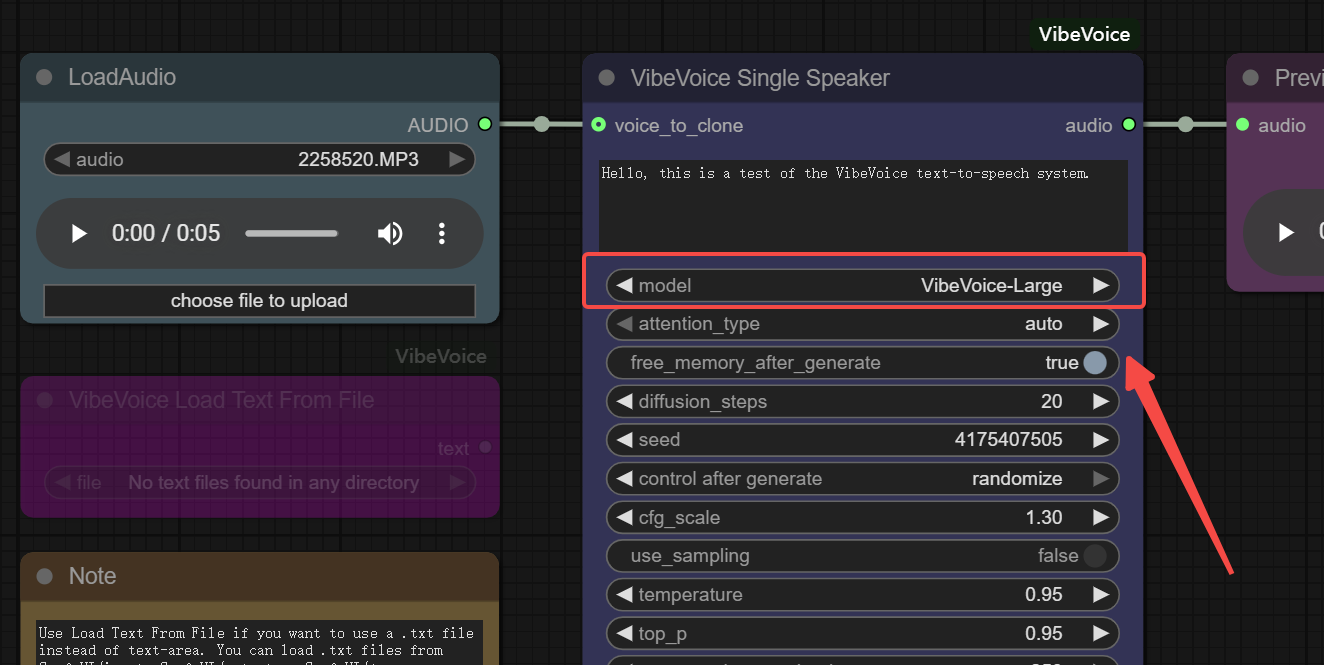
Step 4 : Get Audio