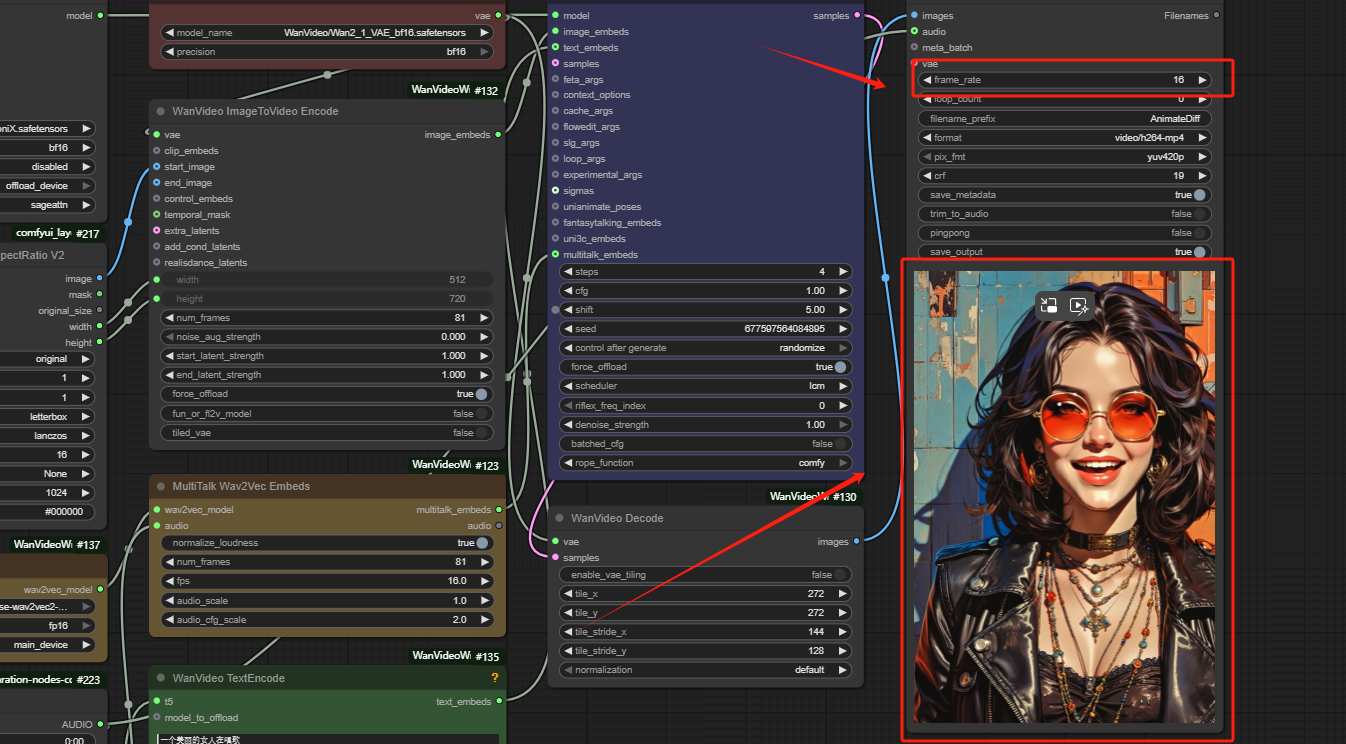
Introduction
MultiTalk is an innovative audio-driven multi-person conversational video generation framework developed by MeiGen-AI. This powerful tool enables users to create realistic videos featuring single or multiple characters engaging in conversations, singing, or interacting based on provided audio, reference images, and text prompts. Key functionalities include precise lip synchronization with audio, support for cartoon character generation, and flexible resolution outputs (480p and 720p) at various aspect ratios. MultiTalk leverages advanced audio processing with Wav2Vec and the Wan2.1 video diffusion model, enhanced by techniques like Label Rotary Position Embedding (L-RoPE) for accurate audio-person binding. It supports streaming mode for long videos and clip mode for short ones, with optional LoRA and TeaCache for optimized performance. This framework is ideal for creating dynamic, interactive, and visually appealing conversational videos for academic and creative applications.
Wan-Video
a comprehensive and open suite of video foundation models that pushes the boundaries of video generation. Wan2.1 offers these key features:
- 👍 SOTA Performance: Wan2.1 consistently outperforms existing open-source models and state-of-the-art commercial solutions across multiple benchmarks.
- 👍 Supports Consumer-grade GPUs: The T2V-1.3B model requires only 8.19 GB VRAM, making it compatible with almost all consumer-grade GPUs. It can generate a 5-second 480P video on an RTX 4090 in about 4 minutes (without optimization techniques like quantization). Its performance is even comparable to some closed-source models.
- 👍 Multiple Tasks: Wan2.1 excels in Text-to-Video, Image-to-Video, Video Editing, Text-to-Image, and Video-to-Audio, advancing the field of video generation.
- 👍 Visual Text Generation: Wan2.1 is the first video model capable of generating both Chinese and English text, featuring robust text generation that enhances its practical applications.
- 👍 Powerful Video VAE: Wan-VAE delivers exceptional efficiency and performance, encoding and decoding 1080P videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
https://github.com/kijai/ComfyUI-WanVideoWrapper
https://github.com/meigen-ai/multitalk
Recommended machine:Ultra-PRO
Workflow Overview
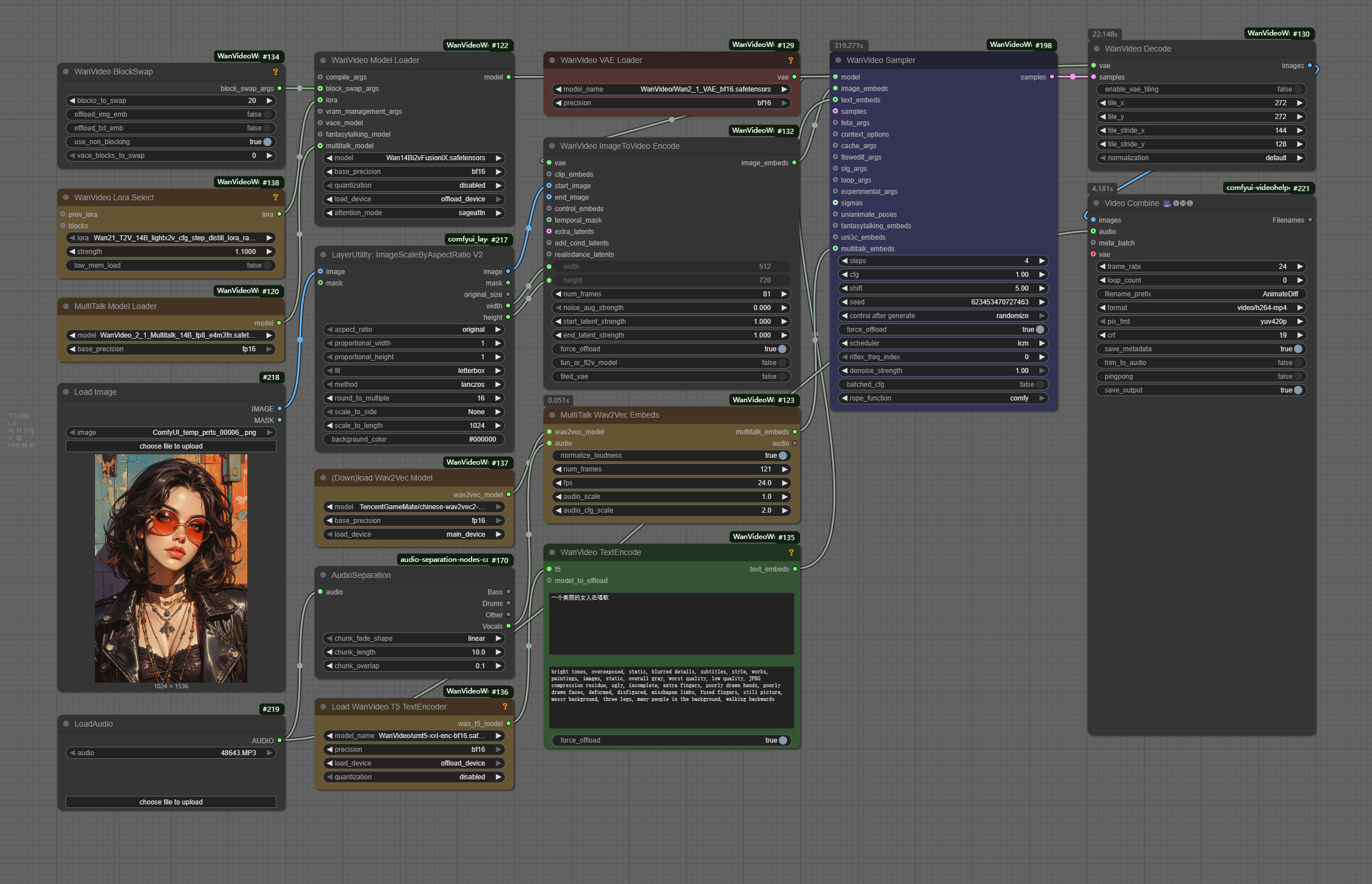
How to use this workflow
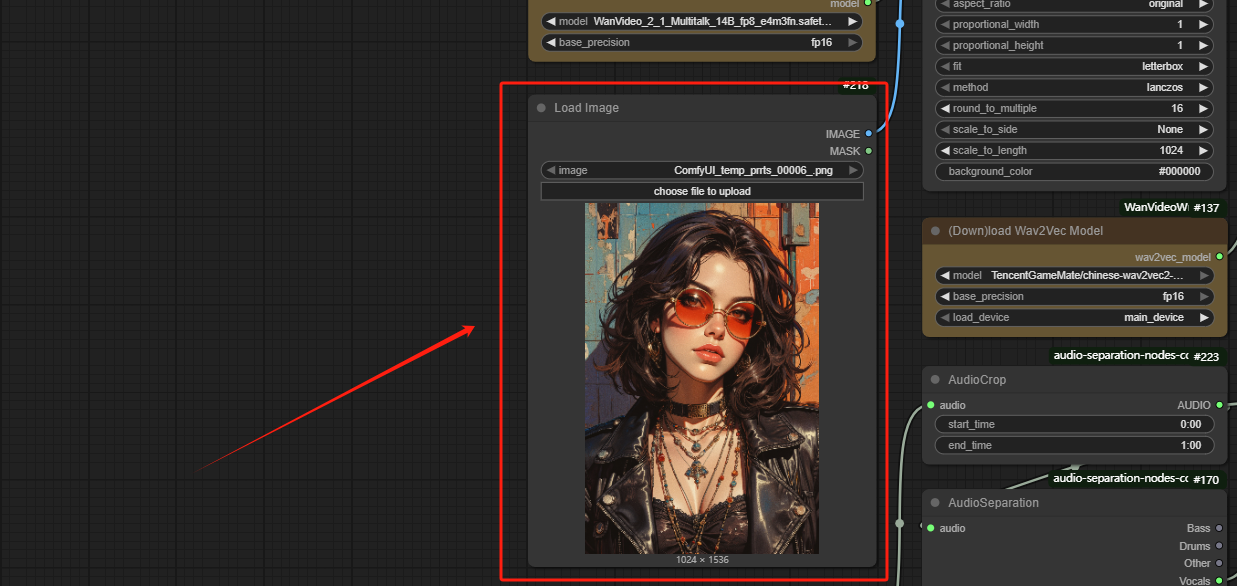
Step 1: Load Image
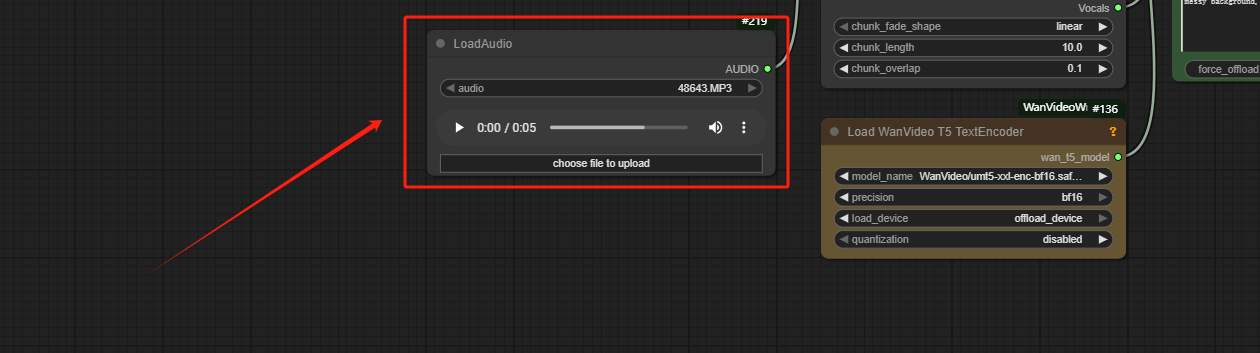
Step 2: Load Audio
Step 3: Adjust Video parameters
- Customize the maximum length of the audio
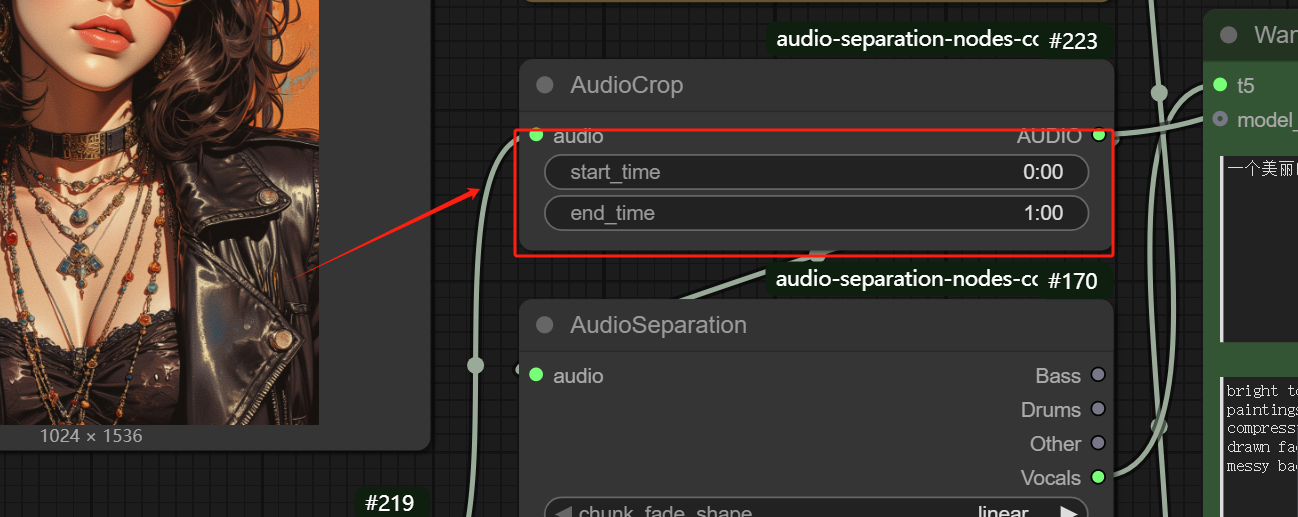
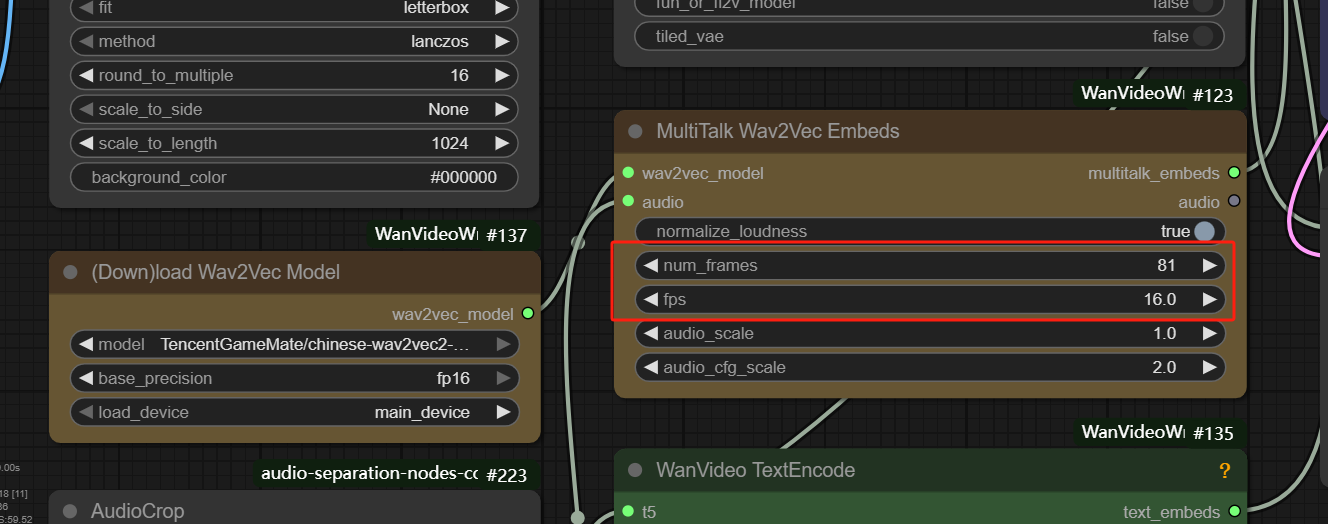
- Customize the length of video, video length = num frames/fps
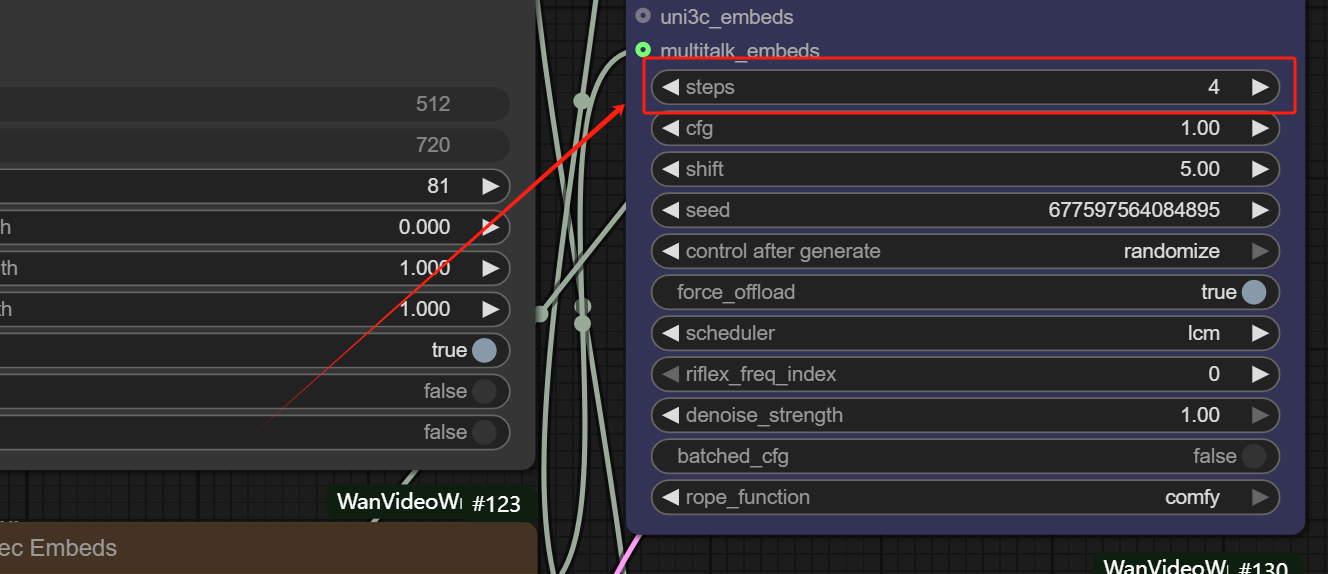
- This model can produce very high-quality audio videos in four steps, and it is not recommended to modify it
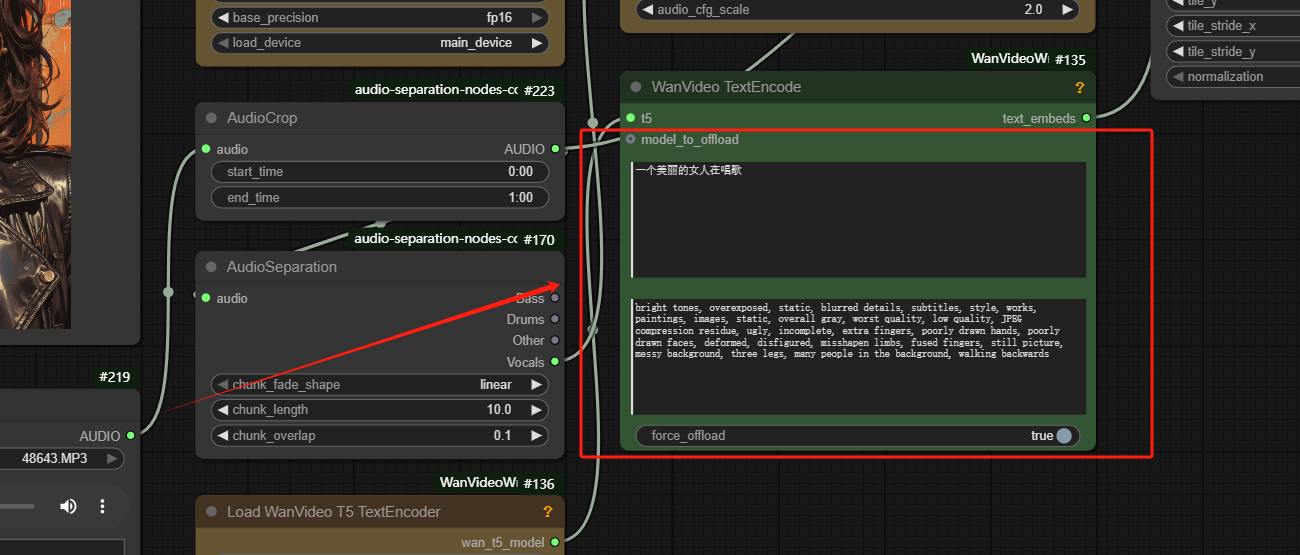
Step 4: Input the Prompt
No need to describe the entire picture in detail, just enter key information such as lens, action, etc.
Step 5: Get Video