The Infinite Talk Workflow is a cutting-edge ComfyUI pipeline built on the WAN framework, designed to create ultra-realistic, infinite-length talking videos from a single image and audio input. This workflow delivers precise lip synchronization, natural head movements, authentic facial expressions, and believable body gestures, resulting in truly life-like AI-generated conversations.
Unlike traditional talking video generators, Infinite Talk can generated long videos based on your GPU capacity, eliminating the need. Whether it’s a narration, podcast clip, or speech animation, this workflow ensures perfect audio-visual alignment with smooth, cinematic-quality output.
Key Features:
🎙 Audio-to-Video Precision – Converts any audio into a natural, expressive talking video.
🧠 WAN-Based Architecture – Utilizes advanced motion and expression modeling for life-like realism.
⚡ Unlimited Video Duration – Generates continuous talking videos (limited only by GPU resources).
👄 Perfect Lip Sync & Expression – Accurately follows speech rhythm, tone, and emotional nuance.
🧍 Full-Body Awareness – Includes head tilts, posture shifts, and subtle movements for realism.
🖼 Simple Inputs – Just upload one image and an audio file to start creating your video instantly.
Why It’s Special:
- No need to calculate frame counts — the system adapts automatically.
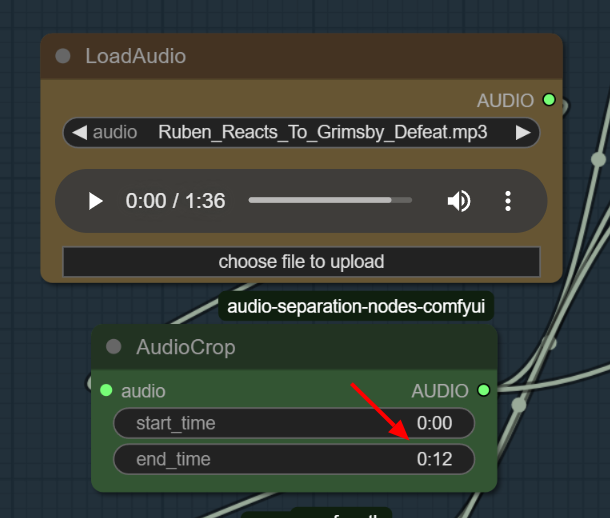
- In case you have a long audio - i've included an audio crop node to crop only the part of the audio you need.
- No lip sync issues — ensures natural speech flow and facial motion.
- This workflow works with a single speaker and if you are looking for multi speakers - wait for my other workflow INFINITE TALK WITH MULTIPLE SPEAKERS.
🚀 Experience Infinite Talk — the most advanced single-speaker talking video workflow in ComfyUI. Create limitless, expressive, and synchronized AI videos with ease.